�P�D�P ���`�[�t�Ƃ�
����{�ƂȂ郂�`�[�t�̒m���ɂ��Ċm�F���s���܂�
���`�[�t�Ƃ͊e��̃^���p�N���̃A�~�m�_�z�ɔF�߂��鏬�����\���������w�����t�ł��B��ʓI�ȃ^���p�N���͍\���Ƃ��ċ�������܂����A�^���p�N��������ɂ��邽�߂̂Q���\���̌��ѕt�����͌����Ă��܂��B���̂��߁A�݂��ɊW�̂Ȃ��^���p�N���ԂŃw���b�N�X�E�^�[���E�փ��b�N�X���̈��̍\�����ǂ��o�����A���̂悤�ȍ\���̂��Ƃ��\�����`�[�t�ƌĂт܂��B�܂��A������R�[�h����A�~�m�_�z��ɂ͓����I�ȃp�^�[��������A���̋Ǐ��I�ɕۑ����ꂽ�u���b�N�ɂ���`�������̂�z�`�[�t�ƌĂт܂��B��\�I�ȃ��`�[�t�Ƃ��Ă͐�قǂ������փ��b�N�X�E�^�[���E�փ��b�N�X�A�W���N�t�B���K�[�A���C�V���W�b�p�[�Ȃǂ�����܂��B������DNA�Ɍ�������Ƃ������ʂ̋@�\�����^���p�N���Ɍ���������I�ȃ��`�[�t�ŁADNA�����̍ۂ̋@�\���ʂ������ɑ��݂��܂��B���C�V���W�b�p�[�̓A�~�m�_�z��̂V�c��ƂɃA�~�m�_�̈�ł��郍�C�V�����o������Ƃ��������I�ȃp�^�[�������݂���ׁA�A�~�m�_�z��ׂ邱�ƂŃ��`�[�t��T���o�����Ƃ��ł��܂��B
�P�D�Q ���`�[�t�����̖ړI
���Ȃ����`�[�t�̌������s�����𗝉����܂��傤
�^���p�N���̃��`�[�t����������ړI�͑傫���Q����܂��B
���@�\�A����ы@�\���ʂ̗\��
�ۑ����ꂽ�z�狤�ʂ̃��`�[�t�������o�����ƂŃ^���p�N���Ԃł̋@�\�̗ގ������������A���m�̃^���p�N���̋@�\��@�\���ʂ𐄒肷�邱�Ƃ��ł��܂��B
�Ⴆ�A���関�m�̃^���p�N���̃A�~�m�_�z����ꂽ�Ƃ��A���`�[�t�̌����������Ȃ��A��̗�ɋ��������C�V���W�b�p�[�����������Ƃ����炻�̃^���p�N����DNA�����^���p�N���ł���A���̍ۂ̋@�\���ʂ͂��̃��`�[�t�ł���Ƃ����������\�ɂȂ�܂��B
���\���̗\��
�^���p�N���̑S�̂̍\�����킩��Ȃ��ꍇ�A�e���`�[�t�̍\���ׁA�����g�ݍ��킹�邱�ƂőS�̂̍\����\������ۂ̎菕���Ƃ��邱�Ƃ��ł��܂��B
�P�D�R ���`�[�t�����v���O�����̎�ނƓ���
���e���`�[�t�����v���O�����̃A���S���Y���Ȃǂ̓����𗝉����܂��傤
��ʓI�ȃ��`�[�t�f�[�^�x�[�X���C�u�����Ƃ����ŗp�����Ă���T�[�`�G���W���A�A���S���Y���͈ȉ��̒ʂ�ł��B
|
���`�[�t���C�u���� |
�T�[�`�G���W�� |
�J���c�� |
�A���S���Y�� |
|
Profilefind |
�_�C�i�~�b�N�v���O���~���O |
||
|
BLAST2(Gapped BLAST) |
|||
|
�B��}���R�t���f�� |
�P�D�S Pfam�f�[�^�x�[�X
��
����g�p���郂�`�[�t�f�|�^�x�[�X��Pfam�ɂ��ė������܂��傤
��ŏq�ׂ��ʂ�A���݃C���^�[�l�b�g��Ō��J����Ă��郂�`�[�t�f�[�^�x�[�X�A���`�[�t�����v���O�����͂���������܂����A����͂��̒���Pfam�f�[�^�x�[�X�Ƃ��̏�œ����Ă��郂�`�[�t�����v���O�������g�p���܂��B
Pfam�͌��ݍł��悭�������ꂽ���`�[�t�f�[�^�x�[�X�̈�ŁA�c��Ȑ��̃^���p�N���t�@�~���[�̃R���N�V������ێ����Ă���A���̐��͌��݂������Â��Ă��܂��B�ő�̓����͌����V�X�e���Ƃ���HMMER�Ƃ����v���O�����𗘗p���Ă���_�ł���A����ɂ�荂���Ő��x�̍������`�[�t�̌������\�ɂ��Ă��܂��B
�P�D�T HMMER
��Pfam�f�[�^�x�[�X��̌����V�X�e���Ƃ��ėp�����Ă���HMMER�ɂ��ė������܂��傤�B
HMMER�̓��V���g����w�ŊJ�����ꂽHMM�iHidden Markov Model�F�B��}���R�t���f���j�𗘗p���ē����̒��o�ƌ������s���V�X�e���ł��BPVM��thread��p���������ɑΉ�����Ȃǂ��Ă����i�I�ȃV�X�e���ŁAGPL�ɂ��������Ĕz�z����Ă��邽�ߎ��R�ɗ��p���邱�Ƃ��\�ł��B
�P�D�U �B��}���R�t�A��
��
HMMER�ŗp�����Ă���B��}���R�t�A�����f���ɂ��ė������܂��傤
�ł��d�v�ȓ����́A�P�ɃR���Z���T�X�z�����������ꍇ�ƈ���āA�z���̎ア�p�^�[�������o���邱�Ƃ��\�ł���A�m�C�Y�����݂���Ƃ��̔z��̃p�^�[���F���ɔ��ɗL���ł���Ƃ����_�ł��B
��̂��Ƃ𗝉����Ă�����HMMER�𗘗p�����ł͖��͂���܂��A�ڂ����͈ȉ��̂悤�Ȃ��̂ł��B
Ø �L���I�[�g�}�g�����g�����ď�ԑJ�ڂɊm���̊T�O���������m���I�[�g�}�g���̈��
Ø �}���R�t�A���̊e��ԂɋL���̏o�͊m����^��������
Ø �ʏ�̃}���R�t�A���Ƃ͂��ƂȂ�A��ԑJ�ڂ̗l�q�͒��ڂɂ͌������A�B��w�Ƃ��Ĉ����邽�߁A�g�B��h�}���R�t�A���ƌĂ��
Ø
�]���͉����F���̕���ł悭���p����Ă���
�Q�D�P Pfam�̃z�[���y�[�W���J��
��
�C���^�[�l�b�g�G�N�X�v���[���[���g���āAPfam�̃z�[���y�[�W�ɃA�N�Z�X���Ă݂܂��傤
�����J����Ă���t���[��Pfam�f�[�^�x�[�X�͂��������݂��܂����A����̓��V���g����w�����J���Ă���f�[�^�x�[�X�𗘗p���܂��B�g�p�ł���@�\�Ƃ��Ă�Sanger�̃z�[���y�[�W���痘�p�ł�����̂̂ق����D��Ă���̂ł����A����͌����ɂ����鎞�Ԃ��d�v�����āA��ԍ����ȃ��V���g����w�̂��̂��g�p���܂��B
|
�Ǘ��g�D |
�����N |
Pfam�̃o�[�W���� |
�^���p�N���t�@�~���[�̐� |
|
���V���g����w |
�U�D�S |
�Q�W�U�U |
|
|
Sanger |
�U�D�S |
�Q�W�U�U |
|
|
CGR-KI |
�U�D�P |
�Q�V�Q�V |
|
|
INRA |
�U�D�Q |
�Q�V�V�R |
�\�DPfam�f�[�^�x�[�X�̃o�[�W�����Ɗ܂܂��^���p�N���t�@�~���[(�Q�O�O�P�N�U������)
�ł́A���ۂɃA�N�Z�X���Ă݂܂��傤�B
�A�@URL�̓���
�A�h���X����http://pfam.wustl.edu/ �Ɠ���

�B
���^�[���L�[�������Đڑ�
�ڑ��ɐ�������Ɖ��}�̃g�b�v�y�[�W���\������܂��B
�i�P�j ���V���g����w�ȊO��Pfam�f�[�^�x�[�X�T�[�o�[��HMMER�A�����ē����ւ̃����N�ł��B
�i�Q�j ���݂�Pfam�̃o�[�W�����ƍX�V���ꂽ�����A�����Č��ݓo�^����Ă���^���p�N���t�@�~���[�̐����\������Ă��܂��B�T�[�o�[�ɂ����Pfam�̃o�[�W�������قȂ��Ă��邱�Ƃ�����̂ŁA�ŐV�̂��̂��g���悤�C�����܂��傤�B
�i�R�j �A�~�m�_�z��ɂ�郂�`�[�t�����y�[�W�ւ̃����N
�C
�A�~�m�_�z��ɂ�郂�`�[�t�����y�[�W���J��
�}���̊ۂł�������PROTEIN
SEARCH�̃����N���N���b�N���Č����y�[�W���J���܂��B
�Q�D�Q�@�A�~�m�_�z��̎擾
��
�Q�m���l�b�g�̃f�[�^�x�[�X�Ō������s���A���`�[�t�������s���^���p�N���̃A�~�m�_�z����擾���܂��B
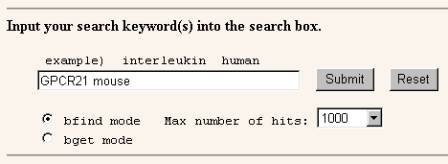
�@ SwissProt�Ō���
�V�����쐬�����E�B���h�E����Q�m���l�b�g�ɐڑ�����SwissProt�ŃA�~�m�_�z��̌����������Ȃ��܂��B���ׂ�^���p�N���̓}�E�X��GPCR21�ł��̂ŁA�L�[���[�h�ɂ�mouse�h, �gGPCR21�h����͂��܂��B
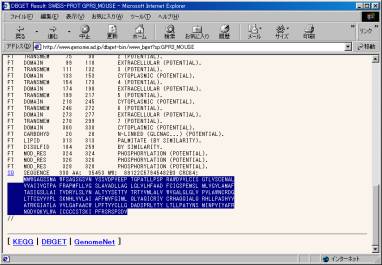
�A �A�~�m�_�z��̃R�s�[
�����̌��ʓ���ꂽ�^���p�N���̃A�~�m�_�z������`�[�t�������s���ׂɃR�s�[���܂��B�y�[�W�̈�ԉ��܂ŃX�N���[�����s���A�A�~�m�_�z��݂̂�I�����A[�ҏW]-[�R�s�[]���s���܂��B
�Q�D�R ���`�[�t�̌���
��
�擾�����A�~�m�_�z��ɑ��ă��`�[�t�������s���܂�
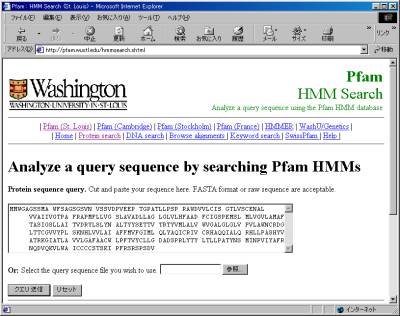
�i�P�j
�z����͗̈�
FASTA�t�H�[�}�b�g�A�������͒P�Ȃ�z��f�[�^����͉\�B�ُ�ȃf�[�^���܂܂�Ă���ƁA�������s��ɃG���[���Ԃ���܂��B
�@ �A�~�m�_�z��̓���
��قǃR�s�[�����A�~�m�_�z����A�z����͗̈��I��������A[�ҏW]-[�y�[�X�g]���s���ē���
�A �����̎��s
�A�~�m�_�z�����͂�����u�N�G�����M�v���N���b�N
�Q�D�S �I�v�V�����̐ݒ�
�������̍ۂ̃I�v�V�����ݒ�ɂ��ė������܂��傤�B
�@����́A�ʏ�̐ݒ�̂܂܂Ō����������Ȃ��܂������A�����̍ۂɂ������̃I�v�V������ݒ肷�邱�Ƃ��ł��܂��B

(1)E-value
cutoff�̓���
�z���E-value�̐؎̂ă��x����ݒ肵�܂��B���̒l��傫�������葽���̃��`�[�t���������ʂƂ��ē����܂����A���܂�傫�Ȓl���g���ƃ��`�[�t�łȂ����̂����`�[�t�Ƃ��ĔF�����Ă��܂��\���������Ȃ�܂��B�t�ɂ��̒l������������Ίm���ȃ��`�[�t�݂̂��������邱�Ƃ��ł��܂��B
�ʏ�͏����l��1�D0�𗘗p���܂��B�����̌��ʁA���`�[�t������������Ȃ��Ƃ��ɂ́A���̒l��10���x�ɑ��₵�čČ����������Ȃ��܂��B
(2)Search
Type�̐ݒ�
Standard
Pram search��Fragment
Pfam search��I�����܂��BStandard
Pfam search�̂ق�����葽���̌������܂����AFragment
Pfam search�̂ق��������I�ȃ��`�[�t�ɑ��č������x�������Ă��܂��B�ʏ��Standard
Pfam search��p���܂��B
�Q�D�T �������ʂ̌���
���������ʂ̌����𗝉����܂��傤
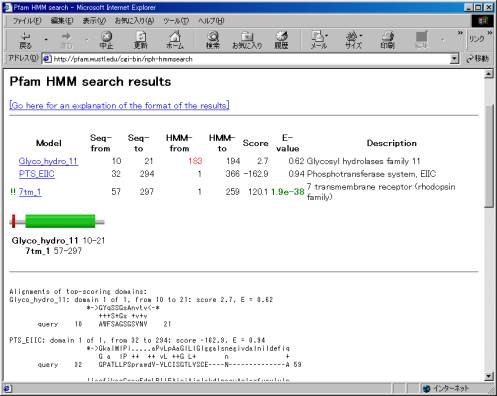
�@�������ʂ̕\����ʂ͑傫���R�̕����ɕ������܂��B
�i�P�j �X�R�A�\����
�i�Q�j ���`�[�t�ʒu�\����
�i�R�j �A���C�����g�\����
�� �X�R�A�\�����̌���

���[�̃}�[�N�̓X�R�A�̔�r���ǂ̂悤�ɂȂ��ꂽ���������Ă��܂��B![]() �}�[�N�̂�����̃��`�[�t�͔��ɗǂ��K�����������̂ŁA�����I��full
alignment���܂߂���r���s��ꂽ���Ƃ������܂��B�܂��A���̏ꏊ��
�}�[�N�̂�����̃��`�[�t�͔��ɗǂ��K�����������̂ŁA�����I��full
alignment���܂߂���r���s��ꂽ���Ƃ������܂��B�܂��A���̏ꏊ��![]() �}�[�N������ꍇ�̓X�R�A���ǍD�ŁA�����炭�ǂ��K���������Ă͂�����̂́A�ʏ�̔�r�����s���Ă��Ȃ����Ƃ������܂��B
�}�[�N������ꍇ�̓X�R�A���ǍD�ŁA�����炭�ǂ��K���������Ă͂�����̂́A�ʏ�̔�r�����s���Ă��Ȃ����Ƃ������܂��B
��Model
�����ɓK���������`�[�t�̃��f�����ł��B�N���b�N����Ƃ��̃��`�[�t�̂��ڂ������邱�Ƃ��ł��܂��B
��Seq-from,
Seq-to
���̃��`�[�t���z���̂ǂ̈ʒu�ɂ��邩�������܂��B�Ⴆ�A��ԉ��̗��
7tm_1�ł���Δz��̂T�V�Ԗڂ̃A�~�m�_����Q�X�V�Ԗڂ̃A�~�m�_�܂ł����̃��`�[�t���\�����Ă��邱�Ƃ��킩��܂��B�X�R�A�̍������`�[�t�ɂ��Ă͉��ŃO���t�B�J���ɕ\������܂��B
��HMM-from,
HMM-to
���̒l���ԂŎ�����Ă���Ƃ��ɂ́A�A���C�����g�����`�[�t�̓r������n�܂��Ă��邱�Ƃ������Ă��܂��B
��Score
�K���������X�R�A�ł��B�l���傫����Α傫���قǂ悭�K�����Ă��܂��B
��E-Value
Expectation
Value�i���Ғl�j�̗��ŁA���R�K�����Ă��܂��ۂ̊��Ғl��\���Ă��܂��B�l���Ⴏ��ΒႢ�قǂ����l�ł���A�悢�l�ɂȂ�ƂP�������Ȃ菬���Ȓl�ɂȂ�܂��BE-Value���D�G�Ȏ��ɂ́iE<0.05�j�A�l�͗ŕ\������܂��B
��Description
���̃��`�[�t�̓����̐����ł��B
�� ���`�[�t�ʒu�\����
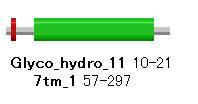
�����Ƃ��X�R�A�̍����������`�[�t�̔z���̈ʒu���O���t�B�J���ɕ\�����܂��B�X�R�A�\������Model�Ɠ��l�ɁA�摜�̃��`�[�t�������N���b�N����ƁA���̃��`�[�t�̏ڍׂȏ��邱�Ƃ��ł��܂��B
�� �A���C�����g�\����

�e�L�X�g�`���œK���������`�[�t�̏��Ƃ��̃A���C�����g��\�����܂��B
2.6 �������`�[�t�����^���p�N���ׂ�
��
�������`�[�t���������^���p�N�����������Ĕ�r���Č��܂��傤�B

���`�[�t�̏ڍו\����ʂ̒��قǂɂ���h���C���\���̉摜�\�������@�\���g���܂��B�A���C�����g�̃^�C�v�͍��܂łƓ��l���hSeed
alignment�h��p���܂��BRetrieve
domain structure���N���b�N����ƁA�ȉ��̉�ʂ��\������܂��B
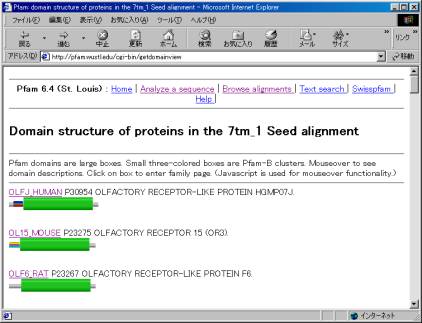
����͓���7tm_1�Ƃ������`�[�t�����^���p�N���̈ꗗ�ł��B�^���p�N���̖��O���N���b�N���邱�ƂŁA���̃^���p�N���̏ڍׂȏ���\�����邱�Ƃ��ł��܂��B���̒��ŏォ���Ԗڂɂ���AOL15_MOUSE���N���b�N���Ă݂܂��傤�B
���ڍׂȕ\�����\������܂��̂ŁA�����������̃^���p�N�������������ǂ�ȃ^���p�N���Ȃ̂���m�邱�Ƃ��ł��܂��B
���ۂɉ��̂ق��փX�N���[�����Ă����Ɨl�X�ȏ�L�q����Ă��܂��B
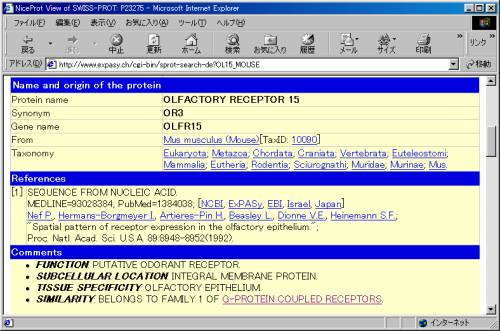
���낢��ȏ�L�q����Ă��܂����A�����Ō��Ăق������́A��ԉ��ɂ���SIMILARITY�̗��ł��B�����̋L�q��������hBELONGS TO FAMILY 1OF
G-PROTEIN COUPLED RECEPTORS�h�Ƃ���܂��B�܂�A�������炱�̃��`�[�t�������̂̒��ɂ�GPCR�����݂��邱�Ƃ��킩��܂��B
����͍ŏ����璲�ׂ�^���p�N����GPCR�ł���Ƃ킩���Ă��܂������A�ʏ탂�`�[�t�������s���A�~�m�_�z��̃^���p�N���͂��̋@�\��\�����قƂ�ǂ킩���Ă��Ȃ����̂ł��B���̂��߁A���̖��m�̃^���p�N���ō����̂悤�Ȍ��ʂ�������A���̃^���p�N����GPCR�A�������͂��̗ގ��̃^���p�N���ł���Ƃ����\���𗧂Ă邱�Ƃ��\�ɂȂ�̂ł��B